股票杠杆网站开户 秘密打造“AI陶哲轩”震惊数学圈!谷歌IMO梦之队首曝光,菲尔兹奖得主深度点评


【新智元导读】19秒破解几何难题,谷歌AI夺得IMO银牌在业界掀起了巨震。就连菲尔兹奖得主陶哲轩,前IMO美国队负责人罗博深都对此大加赞赏。更有AI大佬高调预测,若谷歌继续加码研究,应该可以造出一个「AI陶哲轩」。
谷歌DeepMind正在做的,是要打造出世界上最强的AI数学家。

Perplexity AI的CEO对此做出了大胆预测——DeepMind继续研究下去的话,应该可以搞出一个「AI陶哲轩」了!

这个预测可谓相当大胆。
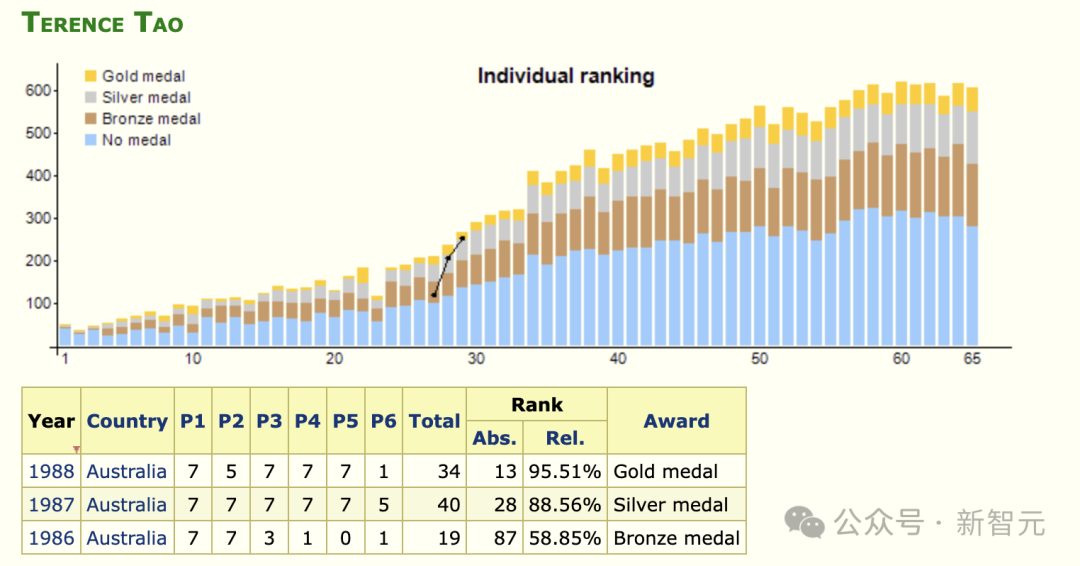
要知道,陶哲轩在IMO竞赛圈,乃至整个数学界,都是传奇般的存在。

「天才出少年」、「数学界莫扎特」,各种溢美之词放到他身上都不为过,毕竟人家首次参加IMO竞赛时只有10岁,是迄今为止最年轻的参赛者。
10岁铜牌、11岁银牌、12岁金牌,一路高歌猛进,他又成为了IMO史上最年轻的金牌得主。
AI大佬能够做出此类预测,正是基于谷歌DeepMind两大AI——AlphaProof+AlphaGeometry 2,上周在IMO 2024竞赛中取得了卓越的成绩。
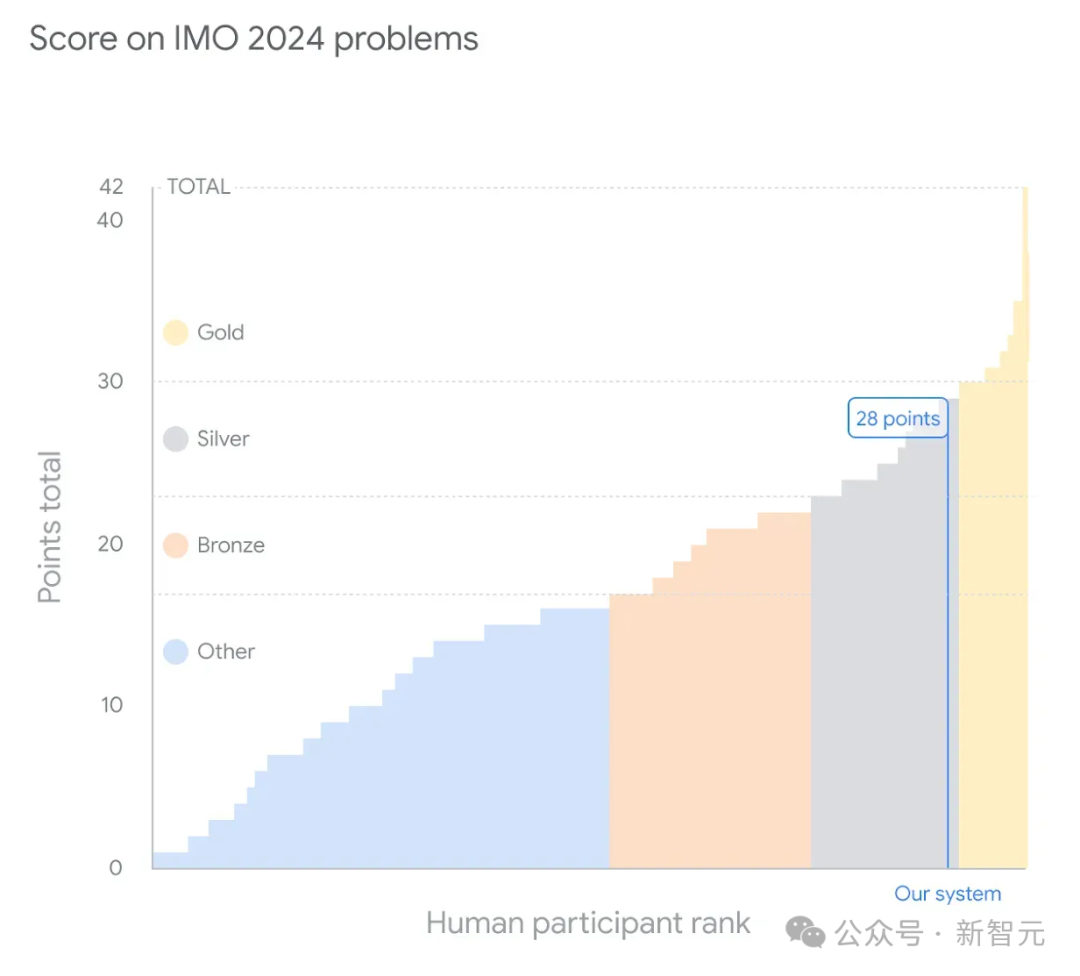
6道题目中,它们一同做对4道,距金牌仅有一分之差(获得28分)。

AlphaGeometry 2效果愈加炸裂,竟可以在短短19秒里,破解了一道几何题目。

然而,这个消息至今余波未平。许多AI界和数学界的大佬们,纷纷给出了自己的思考和感悟。
数学大佬怎么看?
这边隔空被cue的陶哲轩发表了自己的看法。
但人家并不在意所谓的「AI陶哲轩」,而是延续了自己以往的关注点——分析AI和数学将怎样共同发展。

过去几周我一直在旅行,还没有时间完全消化这个消息……但可以在此记录一些初步印象
陶哲轩首先承认,DeepMind做出了一项伟大的工作,拓宽了AI辅助/全自动化方法在基准挑战上的能力边界,再次颠覆了我们的预期。
具体而言,IMO级别的几何问题,对专门的AI工具来说已经是实际可解的问题。
现在看来,能够形式化的,且可以用强化学习过程找到形式化证明的IMO问题,至少在某种程度上都可以被AI攻克(尽管目前每个问题都需要相当程度的算力,以及形式化过程中的人类协助)。
这种方法带来的好处,就是让形式数学更容易自动化,从而有助于包含形式化成分(formal components)的数学研究。
特别是,如果用这种方式创建一个含有形式化证明过程的数据库,并将其公开共享,将成为非常有用的资源。

DeepMind这次的研发路径很聪明,而且事后看来也很合理。他们更多基于强化学习而非大语言模型,有些秉承了AlphaGo的精神,并且非常强调形式化方法。
根据「AI效应」,一旦解释清楚其中的原理,AI就不再像是「类人智慧」的展现,但这依旧扩展了AI辅助工具的能力。
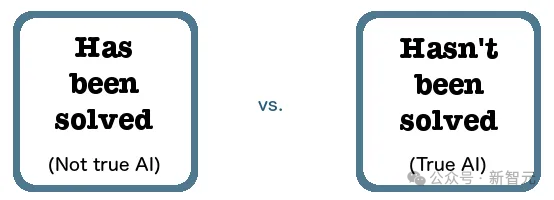
「AI效应」描述一种现象:一旦AI项目取得了某些成功或进展,相关任务就不再被视为AI领域的一部分。类似的还有Tesler定理:「AI是指尚未完成的事情」
值得注意的是,AlphaProof/AlphaGeometry 2与最近获得AIMO冠军的NuminaMath模型,二者不能直接比较。
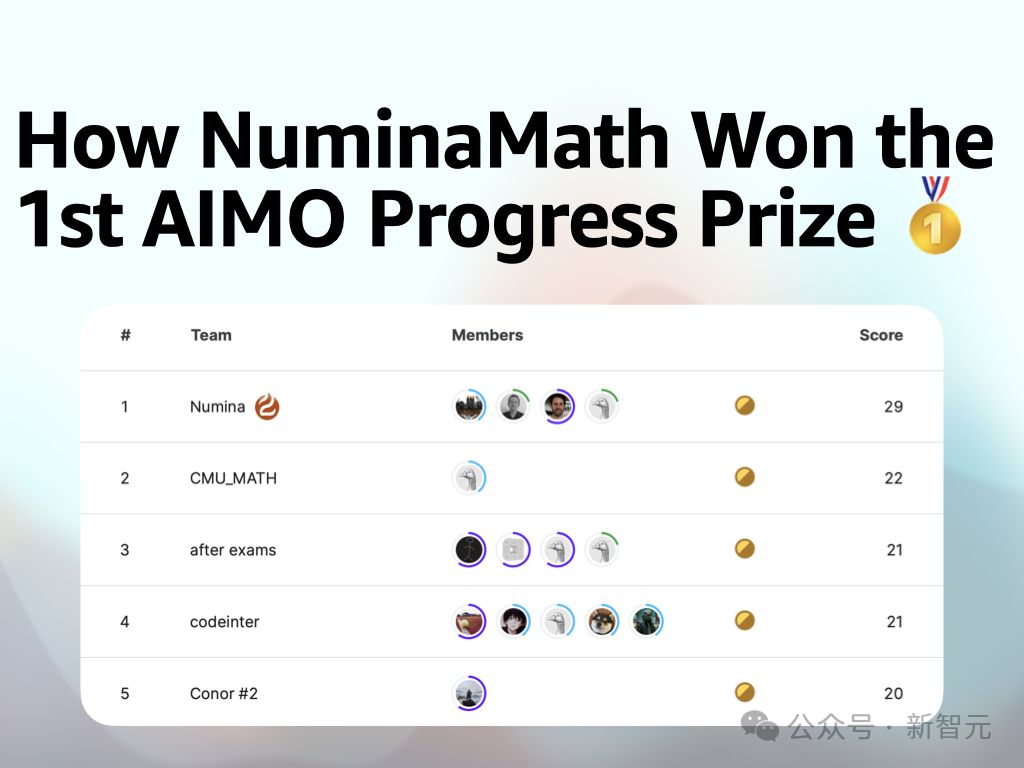
NuminaMath是完全自动化的,资源效率相比DeepMind模型高了搞几个数量级,而且采用了完全不同的思路,即通过LLM生成Python代码,对数字答案进行暴力破解。
由于AIMO所有问题答案都是范围为0~999的整数,因此暴力破解是可行的,但对开放式的IMO赛题就完全不适用了。
NuminaMath也是一项非常好的工作,在数学解题的不同部分中尝试用AI协助或自动化,向我们展示了这个挑战本身的多维性质。
目前,NuminaMath这个冠军模型已经在HuggingFace上开源了7B版本。

与IMO打过多年交道的CMU数学教授罗博深(Po-Shen Loh)也发推表达了自己的震撼。用他的话说,这种感受和当年人们看到苏联第一颗人造卫星Sputnik的感觉是类似的。
他甚至表示,「人类文明需要进入高度戒备状态」。罗博深本人虽然一直期待这种水平的AI能够到来,但他曾经认为,至少还需要几年时间才能达到。

罗博深教授的「震撼」,不仅来自于他数学家的身份,更来自于他对IMO竞赛的多年了解。
1999年,时年17岁的他首次参与IMO竞赛获得银牌,2002年就进入美国IMO国家队训练营担任助理教练,开启了自己长达21年的IMO执教生涯。
2014年,罗博深被正式任命为总教练,随后带领美国队分别在2015年、2016年、2018年和2019年赢得比赛,让1994年后将近20年没有冠军的美国IMO国家队「重回巅峰」。
由于多年执教,罗博深对竞赛的出题流程非常熟悉——IMO会专门选择非标准化问题。
出题小组的重要任务之一就是避免任何类似题目。教练们甚至会翻出一些古老又不为人知的数学竞赛,然后否决掉已经提出的类似题目。
这种题目的创新性让很多人类学生都很难上手,因为学生们也习惯于从例题中学习,记住解题步骤,用来解决相似题目。
以本届IMO的6道题目为例,它们远远超出了任何课程标准。

“全会的举行牵动着我们海外华侨华人的目光。”连日来,英国福建社团联合总会主席李光喜通过互联网持续关注全会相关报道。他说,全会做出的重要部署体现了中国进一步全面深化改革、推进中国式现代化的坚定决心。近年来中国经济展现强大韧性,这得益于中国不断深化改革、推进高质量发展。相信在中国共产党坚强领导下,中国一定能够实现改革发展目标,为世界带来更多发展机遇。
解决这些题目最困难的部分不在于计算,而是需要找到一条解题路径。很多人即使有一整年的时间思考也只能拿到零分。
因此,DeepMind模型在IMO上的胜利和GPT-4在标准化测试上通过「模式匹配」拿到的高分有完全不同的意义。
尽管AI花费的时间远远超出比赛规定,但实现软硬件的加速只是时间问题,模型能够解决这些问题本身就是一个重大进步。
罗博深教授长期致力于数学教育,因此他也会进一步思考——AI具有如此强大的数学能力,这对我们意味着什么?我们能做些什么?
他认为,AI越强大,大幅提升人类智慧就越为重要。
首先就是对就业动态产生的影响。
AI出现以前,个别有非凡能力的人不会真正损害你的就业,因为这样的人终究只是少数。即使这些天之骄子会占据一些职位,余下的工作依旧很多。
然而,一旦AI的能力超越人类,它就可以通过大规模复制,从而夺走所有工作。这与之前的逻辑完全不同。
AlphaProof/AlphaGeometry 2在IMO中的表现已经告诉我们,AI具备了发现新事物的能力(这是最有价值的技能之一),因此整个教育方法都需要快速变革。
无法否认的是,当前的教育结构很大程度上受到考试的影响,为了测试学生在预定义标准上的熟练程度。
然而,现在的每个人都必须学会如何解决从未见过的新问题,否则就无法跟上AI的步伐。
此外,技术越强大,我们就越需要努力保持人类文明中的人性。
这意味着,我们需要建立一个让人们共同合作、互相支持的社区,而不是在「丛林竞争」中互相争斗。分裂则亡。
对我来说,这与构建人类的分析性才能密切相关,因为培养一个试图击败他人而非帮助他人的天才,很可能是有害的。
以上这些观点并非罗博深教授的「纸上谈兵」,也不仅仅停留在提出问题或理念的层面。基于数学教育领域十多年的工作经验,他对此有深入的思考,并试图提出了启发性的解决方案。
数学大佬怎么看?
在谷歌DeepMind伦敦总部的实验室,研究团队在庆祝每次AI里程碑时,内部承袭着一个传统——敲响大锣。
2016年,AlphaGo在围棋比赛中表现优异,锣声响起;2017年,当AlphaZero征服国际象棋时,锣声再次回荡。
每次一敲锣,都代表着算法击败了人类冠军。
就在AlphaProof+AlphaGeometry 2夺得了奥赛IMO 2024银牌的那天,伦敦总部再次敲响了铜锣。
纽约时报的这篇报道深入团队内部,让我们对这位AI数学家有了更深一层的了解。
文章表示,AI越来越擅长数学,并且很快就会成为人类最值得合作的伙伴。
DeepMind数学计划负责人之一Alex Davies表示,这是AI在数学推理方面,取得的重大突破。
7月11日-22日,IMO 2024在伦敦以西约100英里的巴斯大学举行,被公认为是世界上「最聪明的数学天才」参加的顶级数学竞赛。

人类选手(来自108个国家的609名高中生)赢得了58枚金牌、123枚银牌和145枚铜牌。
谷歌AI在答题的过程中,解决了6个问题中的四个,总得分28分,与金牌仅差一分。
对此,谷歌DeepMind研究副总裁Pushmeet Kohli在接受采访时表示,「这并不完美,我们没有解决所有问题。我们的目标是做到完美」。
尽管如此,Kohli博士将这一结果描述为一种「相变」(phase transition),一种革命性的变化,即在数学中使用AI,以及AI系统进行数学运算的能力。
DeepMind实验室邀请了2位独立专家,来评判AI的表现——剑桥大学数学家、菲尔兹奖得主Timothy Gowers,以及软件开发人员Joseph Myers。

他们都曾是IMO竞赛获奖者,纷纷表示对这次AI的表现印象深刻。
过去25年来,Gowers一直对AI与数学结合感兴趣,他认为,「AI已经找到了解决问题的神奇钥匙」。
铜锣敲响
每年IMO,人类选手们都要经过几个月的严格训练,去参加两场奥数考试(共9小时)。
每天仅需做答三题,涉及了代数、组合学、几何和数论。
与此同时,AI数学家也在伦敦实验室里,埋头苦干。
研究科学家David Silver说,「每次系统解决一个问题,我们就敲锣庆祝」。
IMO结果公布那天,中国队中的Haojia Shi是唯一一位获得满分(42分)的参赛者,6道题目分别拿了7分满分成绩。

总榜成绩中,美国队以192分获得第一名,中国以190分获得第二名。

这边,谷歌AI成功破解了4道题——2道代数题、1道几何题和1道数论题,得分28分。它在另外两个组合学问题上,失败了。
与人类选手不同的是,AI答题完全不限时间。
对于某些问题,AI需要长达三天的时间,而学生在每场考试中仅有4.5小时。
Silver博士解释道,「对于谷歌DeepMind团队来说,速度是整体成功的次要因素。因为这实际上只是取决于算力的投入」。

他继续称,「我们能够达到这个阈值,能够解决这些问题,这代表了数学史上的一个重大变化。但也希望能成为一个转折点,让计算机从只能证明简单问题,到证明人类无法证明的问题」。
两大团队,两个AI数学家
几年来,将AI应用于数学一直是DeepMind使命的一部分,而且通常是与世界级的研究数学家合作。
Davies博士表示,数学需要抽象、精确和创造性推理的有趣结合。
他指出,部分原因是这种能力组合,使数学成为达到所谓的AGI这一最终股票杠杆网站开户目标的良好试金石,而且这也是OpenAI、Meta AI、Xai等公司一直在追逐的目标。
因此,奥林匹克数学题已成为公认的一个基准。
今年年初,谷歌DeepMind首次发布AlphaGeometry,解决了奥林匹克抽样的几何问题,水平相当于人类金牌获奖者。

首席研究员Thang Luong在电子邮件中表示,AlphaGeometry2在解决IMO问题上已经超过了金牌得主。

借着这股势头,谷歌DeepMind为这项挑战组建了两个团队:
一个由伦敦的研究工程师Thomas Hubert领导,另一个团队由位于美国Mountain View实验室的Luong博士和Quoc Le领导,每个团队约有20名研究人员。
Luong博士领导的团队名为「超人类推理团队」,目前为止招募了十几名IMO奖牌获得者。

谷歌DeepMind超人类推理团队(superhuman reasoning team)
他自豪地表示,这是目前为止,谷歌内部「IMO密度最高」的团队。
大约20年前,我全身心投入奥数竞赛,在全国获得银牌(当时排名第8),但我没能进入2005年的 IMO比赛.....,时光荏苒,我非常高兴谷歌最新的AI系统(AlphaGeometry2+AlphaProof)帮我实现了「赢得」IMO奖牌的梦想!
时隔半年,谷歌推出迭代后的AlphaGeometry 2,仅用了19秒,解决了IMO 2024的几何问题。
另一波在伦敦总部的团队,由Hubert领队,开发了全新模型AlphaProof。它具有可比性,更加通用,目标是为了解决更广泛的数学问题。
背后算法揭秘
简言之,AlphaGeometry和AlphaProof利用了多种不同的AI技术。
非形式推理系统
AlphaProof是用自然语言表达的非形式推理系统(informal reasoning system)。
它基于谷歌Gemini打造,使用已公开的问题、证明等英文语料库作为训练数据。
非形式系统擅长识别模式,以及提出下一步建议。而且它富有创造性,以一种自然语言可以理解的方式谈论想法。
当然,LLM倾向于编造内容,这对诗歌可能行得通(也可能不是),但对数学肯定不行。
在数学这种情况下,大模型似乎表现出了克制。但这并不是说,它完全免疫于「幻觉」,但频率有所降低。
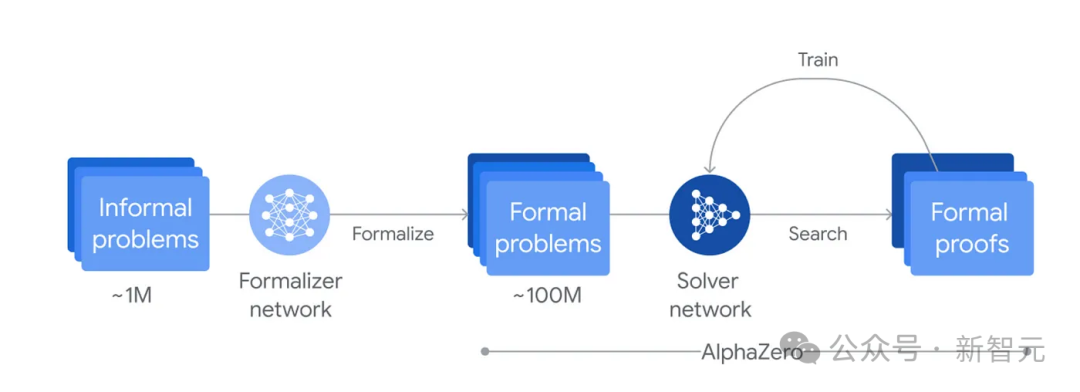
形式推理系统
AlphaGeometry是基于逻辑并用代码表达的形式推理系统。
它使用了名为Lean的定理证明器和证明助手软件。该软件可以确保,如果AI认为证明是正确的,那么它确实是正确的。
Hubert表示,「我们可以准确地检查证明是否正确,因为每一步都保证在逻辑上是合理的」。
而另一个关键组件是,AlphaGo和AlphaZero谱系中的强化学习算法。

谷歌DeepMind负责强化学习的副总裁Silver博士说,「AI可以自主学习,无限扩展」。
「由于RL算法不需要要老师,所以它可以不断地学习,一直学习,直到最终它能够解决人类可以解决的最困难的问题」。
这也是AlphaZero所经历的现实,从0开始学习,仅通过玩游戏,在不到一天时间内,就能重新发现国际象棋中的所有知识。
在大约一周的时间,它便发现了围棋的所有知识。所以我们想,把这个AI能力应用到数学中。
数学家,会被AI取代吗?
菲尔兹奖得主Gowers并不担心AI数学家,带来的长期后果。
我们可以假想这样一种情况,数学家基本上没有什么可做的了。如果计算机在数学家目前做的所有事情上都变得更好、更快,那就会是这种情况。
不过,在AI能够进行研究级数学之前,似乎还有很长的路要。
他补充道,「如果谷歌DeepMind能至少解决一些棘手的IMO问题,那么一个有用的研究工具就不会太遥远」。
而一个真正熟练的AI工具,可能会让数学更容易上手,加速研究过程,还能让数学家跳出固有思维。
最终,它甚至可能提出引起共鸣的新奇想法。